

Fine-Tuning LLMs: Full Fine-Tuning, PEFT, LoRA, QLoRA


Large Language Models (LLMs) have exploded into the mainstream, transforming everything from customer support to creative writing. But to truly unleash their power for specific applications, we need to fine-tune them.
In this guide, you’ll learn:
What fine-tuning really means
How supervised fine-tuning works (with code)
Why full fine-tuning can be expensive and risky
How PEFT techniques like LoRA, Prefix-Tuning, and QLoRA make fine-tuning cheaper and accessible — even on consumer hardware
A practical example of fine-tuning an LLM on a toy dataset
Let’s dive in!
What is Fine-Tuning?
Think of LLM training in two phases:
Pretraining
The model learns general language knowledge from vast datasets like Wikipedia, books, code, and web pages.
It discovers grammar, reasoning patterns, world knowledge, etc.
Fine-Tuning
We adapt the pretrained model to a specific task or domain:
Legal documents
Customer support chat
Medical text analysis
Financial reports
Without fine-tuning, even the most powerful model might fail on specialized tasks or instructions.
Why Do We Need Fine-Tuning?
Fine-tuning serves two main purposes:
Domain adaptation
E.g. A model pretrained on general text won’t know specialized medical jargon until you fine-tune it.Instruction tuning
Teaching a model to reliably follow instructions:“Summarize this text.”
“Translate English to French.”
Supervised Fine-Tuning (SFT)
Most LLM fine-tuning is supervised. We show the model:
Input text
Desired output text
…and optimize it to predict the output correctly.
SFT Loss Function
In supervised fine-tuning, we usually minimize cross-entropy loss, measuring how well the model’s predicted token probabilities match the target tokens.
In mathematical terms:
where.
w_t = target token at step ttt
w_<t = tokens generated so far
θ = model parameters
Training updates the model’s weights to minimize this loss.

SFT Code Example (Hugging Face Transformers)
Let’s fine-tune LLaMA-3 on our toy translation dataset:
from transformers import AutoTokenizer, AutoModelForCausalLM, Trainer, TrainingArguments
import torch
# Load model and tokenizer
model_name = "meta-llama/Meta-Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Tiny toy dataset
texts = [
"Translate 'cat' to French -> chat",
"Translate 'dog' to French -> chien",
]
labels = texts.copy()
# Tokenize
encodings = tokenizer(
texts,
padding=True,
truncation=True,
return_tensors="pt"
)
# Labels should match input IDs for language modeling
encodings["labels"] = encodings["input_ids"]
# Training setup
args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=2,
learning_rate=2e-5
)
trainer = Trainer(
model=model,
args=args,
train_dataset=torch.utils.data.TensorDataset(
encodings["input_ids"],
encodings["attention_mask"],
encodings["labels"]
)
)
trainer.train()This teaches the model to map our simple inputs to the desired translations.
Why Full Fine-Tuning is Challenging
Full fine-tuning updates every single parameter in the model. That sounds good for flexibility—but it’s costly and risky.
Consider some modern LLMs:
LLaMA2-7B → ~7 billion parameters
LLaMA3-8B → ~8 billion parameters
Mistral-7B → ~7 billion parameters
GPT-3 (davinci) → ~175 billion parameters
Problems with Full Fine-Tuning
Compute costs skyrocket
Memory consumption is huge
Risk of catastrophic forgetting (the model loses general knowledge)
Higher risk of overfitting if your new dataset is small
This is why many people avoid full fine-tuning—and instead turn to PEFT.
Introduction to PEFT (Parameter-Efficient Fine-Tuning)
Parameter-Efficient Fine-Tuning (PEFT) is a clever idea:
Instead of updating all the model’s parameters, we only train a small set of new parameters, leaving the original model mostly untouched.
Benefits:
Huge savings in memory and compute
Less risk of overfitting
Often surprisingly high performance

Popular PEFT Methods
Here’s a quick tour of PEFT techniques you’ll see in practice:
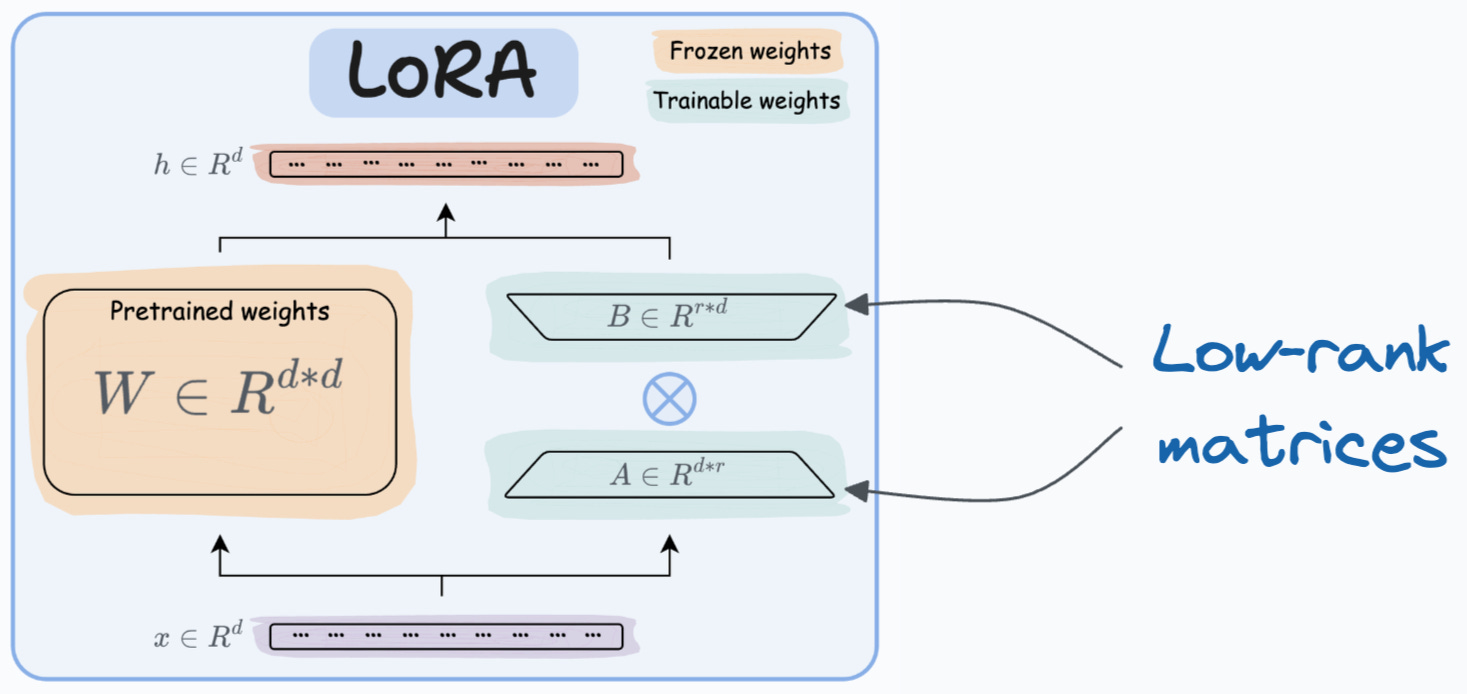
LoRA (Low-Rank Adaptation)
Instead of updating full weight matrices WWW, LoRA inserts low-rank updates:
A and B are tiny matrices (rank 8 or 16 vs thousands of dimensions in W).
LoRA introduces only a few million new parameters—even for giant models.
Analogy: Instead of rewriting an entire document, you’re leaving sticky notes with small corrections.
LoRA Code Example
Using Hugging Face’s peft library:
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Meta-Llama-3-8B"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)Prefix-Tuning
Rather than touching weight matrices, Prefix-Tuning:
Learns virtual tokens (prefix vectors)
These are prepended to the input sequence
The model’s attention mechanism uses them to steer the generation
Analogy: Like whispering instructions into the model’s ear before it answers.
Prefix-Tuning Code Example
from peft import PrefixTuningConfig, get_peft_model
prefix_config = PrefixTuningConfig(
num_virtual_tokens=20,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, prefix_config)Adapter Layers
Adapters insert small MLP layers between the main layers of the transformer. These adapter layers are trained, while the main model weights stay frozen.
Extremely lightweight
Easy to mix and match for different tasks
QLoRA (Quantized LoRA)
QLoRA combines two ideas:
Quantize the model to 4-bit precision (dramatically saving memory)
Apply LoRA on top for efficient fine-tuning
Benefits:
Massive memory savings
Run big models on consumer GPUs
Minimal loss in model quality
Analogy: Shrinking the model to fit into a smaller suitcase—and then customizing it with stickers (LoRA).

QLoRA Code Example
Example with Hugging Face + bitsandbytes:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="bfloat16"
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config
)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)How the Methods Compare
Instead of a table, here’s a summary in words:
Full Fine-Tuning
Trains all parameters.
Highest flexibility and performance.
Requires huge compute and memory.
Best for big enterprise use-cases with large proprietary data.
LoRA
Trains a small number of low-rank matrices.
Saves massive memory.
Good for prototyping and production.
Prefix-Tuning
Adds virtual tokens to steer attention.
Extremely lightweight.
Good for task-specific adjustments.
QLoRA
Combines quantization + LoRA.
Enables big models on smaller GPUs.
Great for cost-conscious fine-tuning.
Fine-Tuning in Practice: LoRA with SFTTrainer
Let’s fine-tune an LLaMA3 model on a tiny instruction dataset using LoRA and the new SFTTrainer from Hugging Face’s trl library.
Suppose you have a dataset like this:
"Translate 'cat' to French -> chat"
"Translate 'dog' to French -> chien"
"Summarize: Artificial Intelligence is transforming industries. -> AI changes industries."Install Required Libraries
Make sure you install the following:
pip install transformers accelerate peft datasets trl bitsandbytesPreparing the Dataset
Let’s wrap our toy examples in a Hugging Face Dataset:
from datasets import Dataset
data = [
{"text": "Translate 'cat' to French -> chat"},
{"text": "Translate 'dog' to French -> chien"},
{"text": "Summarize: Artificial Intelligence is transforming industries. -> AI changes industries."}
]
dataset = Dataset.from_list(data)Load LLaMA-3 and Configure LoRA
Here’s how to load the model and attach LoRA adapters:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig
from trl import SFTTrainer
model_name = "meta-llama/Meta-Llama-3-8B"
# For large models, use 4-bit quantization to save memory
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype="bfloat16",
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# If model doesn't have a pad token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# Configure LoRA
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)Training with SFTTrainer
Now we set up the SFTTrainer:
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=lora_config,
dataset_text_field="text",
max_seq_length=128,
tokenizer=tokenizer,
args={
"output_dir": "./llama3-lora-finetune",
"per_device_train_batch_size": 2,
"gradient_accumulation_steps": 4,
"num_train_epochs": 2,
"learning_rate": 2e-5,
"logging_steps": 1,
"save_strategy": "no"
}
)…and train!
trainer.train()This automatically:
✅ Tokenizes the dataset
✅ Handles labels for causal LM loss
✅ Applies LoRA adapters
✅ Freezes base model weights
✅ Trains only the LoRA parameters
Generating from the Fine-Tuned Model
After training, test your fine-tuned model:
prompt = "Translate 'dog' to French ->"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(output[0], skip_special_tokens=True))You should get:
Translate 'dog' to French -> chienWhen to Use What?
Use Full Fine-Tuning if:
You have significant compute resources.
You’re handling domain-specific data at scale.
You want maximum flexibility.
Use LoRA if:
You want fast experiments.
You’re deploying custom models but can’t afford full fine-tuning costs.
Use QLoRA if:
You have limited GPU resources.
You want to fine-tune bigger models on consumer-grade hardware.
Use Prefix-Tuning if:
You only need subtle task-specific changes.
You prefer ultra-light fine-tuning.
Final Thoughts
Fine-tuning LLMs used to be reserved for big tech. Thanks to PEFT methods, even individuals or small startups can customize giant models without going bankrupt.
Whether you’re fine-tuning LLaMA, Mistral, or GPT-family models, the new tools and libraries make it easier than ever.
Happy fine-tuning!
I was working on developing an AI Agent using Open Source LLM as part of pre internship work and this article helped a lot.