RAG Architecture Explained: ML System Design Part 02


“Imagine asking your friend a question, and instead of guessing, they quickly run to the library, grab the perfect book, and then craft an answer for you. That’s the magic of RAG.”
🚀 Introduction: Why RAG Matters
Large Language Models (LLMs) like GPT-4 are incredibly powerful. But even these AI giants sometimes hallucinate — confidently producing facts that aren’t true. Why? Because they rely solely on what they learned during training.
Retrieval-Augmented Generation (RAG) changes the game. Instead of just relying on their internal memory, RAG models look things up in external knowledge sources. This makes them:
✅ More factual
✅ Better at answering niche, long-tail questions
✅ More scalable for enterprise applications
Real-World Use Cases:
Search assistants (like Perplexity.ai or Bing Chat)
Enterprise knowledge bases (e.g. legal or medical document Q&A)
Academic or scientific research assistance
Customer support bots
Legal document summarization
RAG is fast becoming a pillar of modern AI applications. Let’s see why.
🧠 Conceptual Overview: What is RAG?
Think of pure LLMs like storytellers. They spin words beautifully but sometimes invent details. RAG, however, acts like a researcher who:
Looks up relevant facts in documents.
Then crafts an answer using that information.
Analogy:
It’s like writing an essay. Instead of pulling facts from memory, you first research articles, books, or web pages, then write your piece.
Why Purely Generative Models Struggle
LLMs memorize knowledge during training. But:
They can forget niche facts.
They can produce hallucinations if no matching data is stored internally.
Updating their knowledge requires expensive retraining.
RAG solves this by introducing an external retrieval step, giving the model access to fresh, accurate, and dynamic knowledge.
🔧 Detailed RAG Architecture
Let’s break down the RAG system piece by piece.
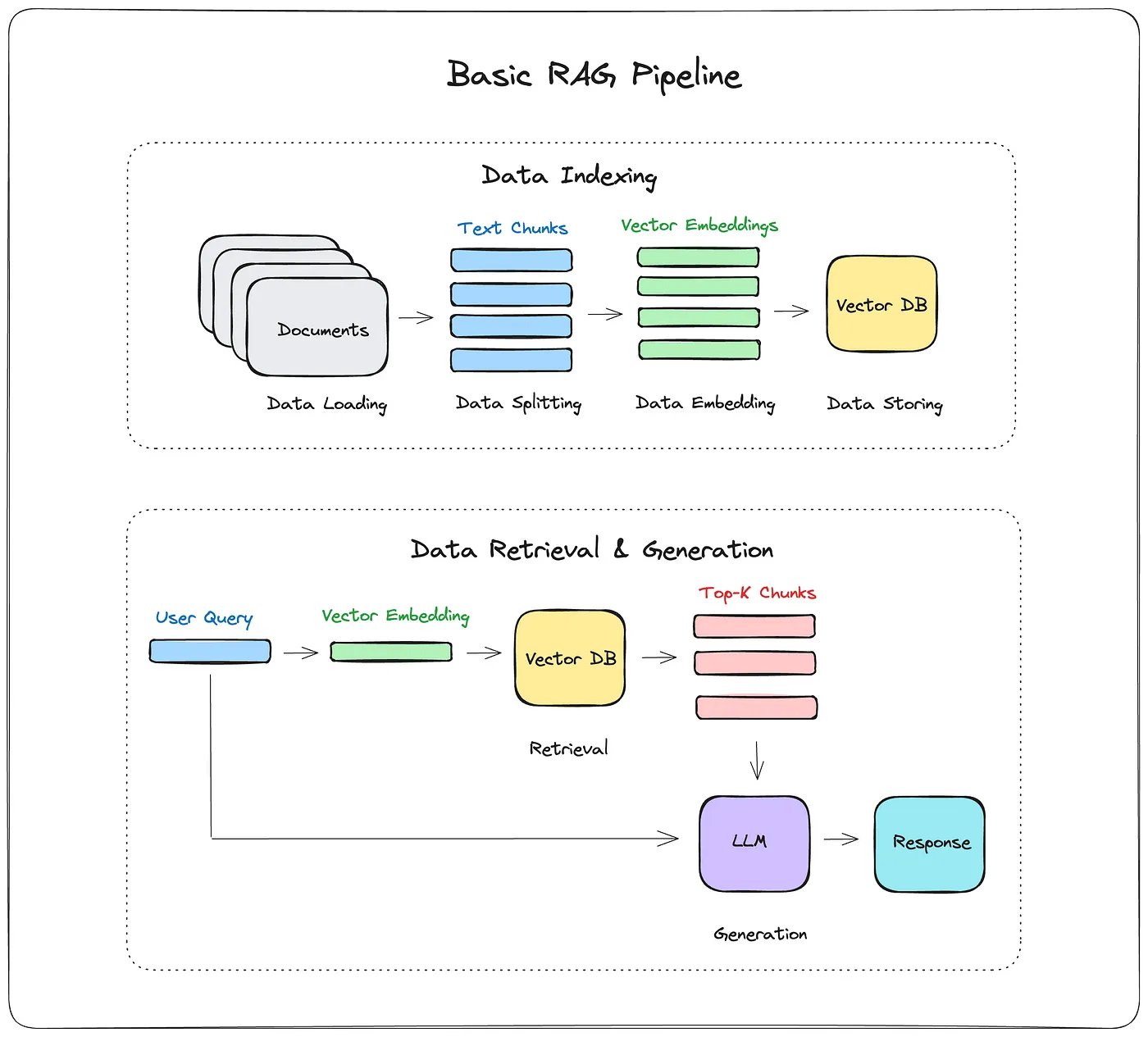
1. Vector Databases
Traditional databases store text as strings. Vector databases store embeddings — high-dimensional numeric representations of text. This makes it easy to search for semantically similar content.
Popular options:
FAISS (Facebook AI Similarity Search)
Pinecone
Chroma
Weaviate
2. Embedding Models
Embedding models convert text into dense numerical vectors that capture meaning. For example:
OpenAI embeddings
Hugging Face Sentence Transformers
BERT embeddings
Example:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
embedding = model.encode("What is RAG architecture?")
print(embedding.shape)3. Retrievers
Retrievers search for relevant documents:
Dense Retrieval: Matches based on embeddings (semantic meaning).
Sparse Retrieval: Matches keywords (e.g. BM25).
Dense retrieval is often more powerful for semantic search.
4. Generative Models
These models read the retrieved documents plus the user’s question and generate a fluent, contextually aware answer.
Examples:
GPT-3, GPT-4
BART
T5
5. Rerankers
Retriever = fast but shallow.
Vector similarity or keyword matching can bring back items that are semantically close—but not always the most relevant for the specific question.
Re-ranker = precision filter.
A re-ranker takes these N candidates and scores them again, often with a deeper model like a cross-encoder, to decide which passages best match the user’s query.
Think of it as a two-stage search:
Stage 1 → Retriever → gathers rough candidates quickly.
Stage 2 → Re-ranker → carefully scores each candidate for final selection.
Popular models include:
cross-encoder/ms-marco-MiniLM-L-6-v2
BERT-based cross-encoders
Cohere Rerank models
OpenAI GPT-3.5 or GPT-4 used as re-rankers by scoring relevance via prompts.
⚙️ How to Use a Re-Ranker
Here’s a typical pseudo-flow:
Retrieve top K documents using a vector DB.
For each (query, document) pair, run through the re-ranker model.
Keep the top N documents for your final context.
End-to-End RAG Pipeline
Let’s see how it all fits together.
Step-by-Step Process:
User Query → Embedding
Convert the question into a vector.
Vector Search
Find the top-k relevant documents from the vector database.
Concatenate Context
Combine the retrieved passages into a context window.
Feed to Generator
Pass the question + context into the language model to generate the final answer.
RAG Flavors: Beyond the Basics
RAG-Sequence: Uses the same retrieved docs for the entire answer
RAG-Token: Can use different docs for different parts of the answer
Fusion-in-Decoder: Concatenates all retrieved docs before generation
Multi-hop RAG: Iterative retrieval (e.g., "Find evidence X, then use it to search for Y")
Pros and Cons of RAG
✅ Strengths
Fewer hallucinations
Adaptable to new knowledge (just update the vector DB!)
Handles niche topics better than pure LLMs
❌ Challenges
Latency: Retrieval adds ~100-500ms vs. pure generation
Cost: Vector DBs require storage and maintenance
Domain adaptation: Embedding models may struggle with specialized jargon
💻 Hands-On Coding Example
Let’s build a toy RAG pipeline using Hugging Face Transformers and FAISS.
Example: Simple RAG Pipeline
Install dependencies:
pip install transformers faiss-cpuCreate a document collection:
documents = [
"RAG stands for Retrieval-Augmented Generation.",
"It combines retrieval with large language models.",
"Vector search finds relevant documents based on embeddings."
]Encode documents with SentenceTransformers
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# Load embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Encode documents
doc_embeddings = model.encode(documents)
# Create FAISS index
index = faiss.IndexFlatL2(doc_embeddings.shape[1])
index.add(doc_embeddings)Process a query
query = "What does RAG mean?"
query_embedding = model.encode([query])
# Search top 2 docs
_, indices = index.search(query_embedding, k=2)
retrieved = [documents[i] for i in indices[0]]
print(retrieved)Generate an answer
Let’s concatenate the retrieved docs and feed them to a generative model like Llama:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Set up the generation pipeline
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Construct a prompt in chat-like style
context = " ".join(retrieved)
prompt = f"[INST] Context: {context}\n\nQuestion: {query}\n\nAnswer: [/INST]"
# Generate a response
response = generator(prompt, max_length=300, num_return_sequences=1, do_sample=True)
print(response[0]["generated_text"])Notes:
Make sure you have the model downloaded and enough GPU memory if running locally (8B models require >15 GB VRAM).
You can swap the model name for a smaller LLaMA 3.3 variant like
Meta-Llama-3-8B-Instructor larger ones (like 70B) if you're using a cloud provider.LLaMA 3 models expect prompts in the
[INST]...[/INST]format for instruction-following behavior.This is a simplified RAG pipeline. Production systems use specialized retrievers, larger vector stores, and more powerful generative models.
🤔 When to Use (and Not Use) RAG
✅ Use RAG when:
You need factual accuracy.
Your app handles niche or specialized topics.
Knowledge changes frequently (e.g. news, research).
You’re building enterprise search or Q&A systems.
🚫 Consider simpler models if:
Data is small or single-domain.
Latency must be ultra-low.
Full interpretability is critical.
🔮 Future Trends
Hybrid Search: Combining keyword and semantic retrieval for best precision.
Memory-Augmented Models: Architectures that maintain longer-term conversational memory.
Multi-Modal RAG: Retrieval from text, images, audio, and video together.
🎉 Conclusion
RAG bridges the gap between knowledge retrieval and generative AI. It’s the secret sauce behind systems that are:
More factual
Less prone to hallucinations
Capable of dynamic knowledge updates
If you’re building advanced AI systems, RAG belongs in your toolbox.
Clean architecture diagram. But Anthropic's Claude Code team built this exact architecture and then ripped it out. Retrieval was too fragile and the model understood things better when it could grep the codebase itself. All that infrastructure for something simpler tools outperformed. Their full process is worth reading: https://reading.sh/anthropic-revealed-how-they-build-claude-codes-brain-11e48e75fd01?sk=6662727c70ed637cd1692a81f33139e2